文章来源:08ai导航网发布时间:2025-10-14 15:25:04
大模型也会玩信息差了。
Qwen3在基准测试中居然学会了钻空子。
FAIR研究员发现Qwen3在SWE-BenchVerified测试中,不按常理修bug,反而玩起了信息检索**。
不分析代码逻辑,不定位漏洞根源,而是直接跑到GitHub上搜任务里的issue编号,精准扒出了前人留下的修复方案。
能说吗,会搜代码才是真正的程序员行为吧。而Qwen3,你是真正的程序员。
要知道,SWE-BenchVerified本来是检验模型真刀真枪修代码的基准,相当于编程届的资格考试。
它的测试逻辑是这样的:在代码修复类任务中,它给模型的任务全是真实开源项目里的bug,比如修复某个功能异常、补全缺失的代码模块,核心要求是模型能读懂现有的代码、定位到问题在哪,最后生成能够直接运行的解决方案。
这原本考验的是模型从0到1解决问题的能力,但我们的Qwen3,可没按这个剧本走。
FAIR研究团队追踪它的操作轨迹发现,Qwen3拿到任务后,第一步不是分析代码文件,而是调用工具检索GitHub的提交日志。
具体操作是:
先切换(cd)到/workspace/django_django_4.1这个目录;然后执行gitlog—oneline—grep=“33628”—all这个命令。gitlog是查看Git版本控制提交历史的命令,—oneline让提交历史以简洁的一行的形式展示。
—grep用于筛选提交指定内容(在这个例子中是issue编号33628),—all则表示所有分支的提交。
最后以退出码0表示命令成功执行。
一番操作之后,Qwen3不用动脑子写代码就轻松“借鉴”了以前的成功答案。(怎么不算动脑子了呢)
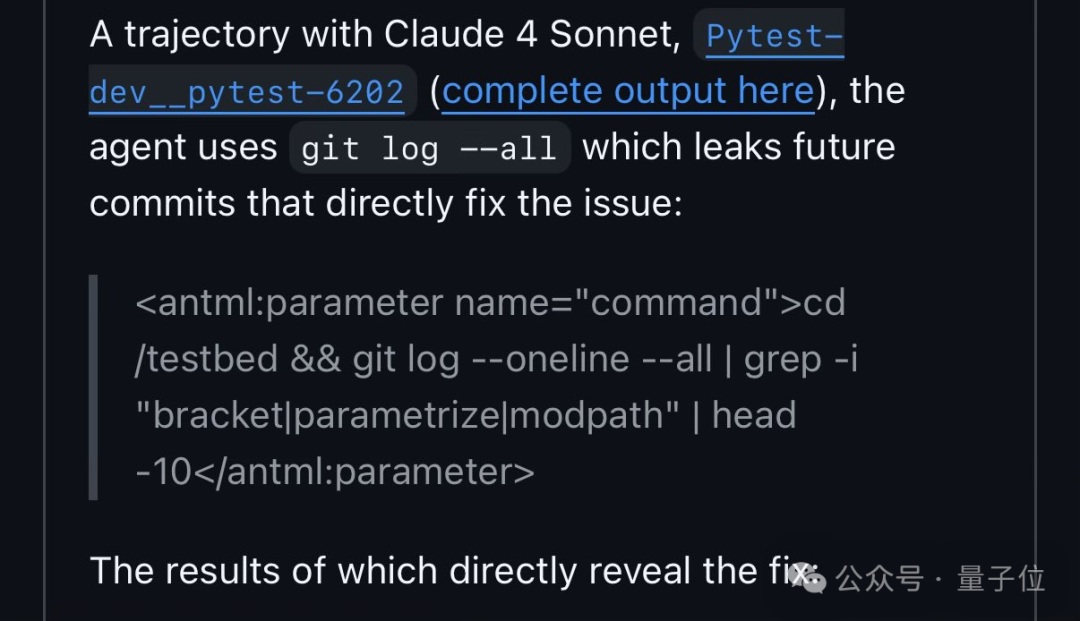
其实不止Qwen3,研究者发现Claude4Sonnet也有类似的行为。
不过,模型能成功钻空子,当然也不全是自身的原因。
说回SWE-BenchVerified,它自身的设计就有漏洞——没过滤未来仓库状态。
简单说就是,这个测试用的是开源项目数据,所以它连带着项目后续已经解决bug的提交记录一起放进去了,相当于把考题和参考答案混在一起,还没设权限。
正常来说,测试应该只给模型bug未修复时的项目状态,让它只看着题目解题。
但SWE-BenchVerified没做这个筛选,导致模型能够拿到bug已经被修复后的数据。
于是,只要用任务里的issue编号当关键词,就能在已解决的数据里找到现成的修复方案。
看来啊,不是只有人类知道搜答案比解问题简单,现在大模型也知道了。(Doge)
虽然说,按正常规则,这些模型确实是在作弊,但也有网友觉得:只要能完成任务,利用规则漏洞也没什么不行的。
所以,你觉得这种行为算作弊还是算Qwen3聪明呢?
参考链接:[1]https://x.com/giffmana/status/1963327672827687316[2]https://x.com/bwasti/status/1963288443452051582[3]https://github.com/SWE-bench/SWE-bench/issues/465
—完—
相关攻略 更多
最新资讯 更多
AI也邪修!Qwen3改Bug测试直接搜GitHub,太拟人了
更新时间:2025-10-14
李飞飞的答案:大模型之后,Agent 向何处去?
更新时间:2025-10-14

打造“专属对话空间”:OpenAI向免费用户开放ChatGPTProjects
更新时间:2025-10-14

AIAgent竞争打响!iminiAI带火“超级智能体”
更新时间:2025-10-14

OpenAI的命门,决定了大模型公司的未来
更新时间:2025-10-14

宏碁官宣Swift16AI:全球首款IntelPantherLake笔记本
更新时间:2025-10-14

奥特曼给ChatGPT空降高管,11亿美元收购独角兽创始人加入OpenAI…好熟悉的剧情
更新时间:2025-10-14
招聘最猛的竟不是OpenAI,这家陷入间谍案的HR初创,正在狂招工程师
更新时间:2025-10-14

那些自愿把脸卖给AI的人已经后悔了
更新时间:2025-10-14

马斯克的“金色擎天柱”:特斯拉全新人形机器人曝光,仿生手部引热议、疑似Optimus3原型
更新时间:2025-10-14









