简介
一个名叫「Music To Image」应用程序在Hugging Face社区横空出世后,直接热度飙升,冲上了本周热搜榜,让人们看到了「音生图」的潜在可能性。
简而言之,只要上传一段音乐,它就能根据音乐旋律和歌词,生成一张对应意境的图片。

玩法也十分简单,只需在页面上拖拽或者上传一段音频文件,支持MP3/WAV等常见音频格式,AI会直接调用AI绘画工具Stable Diffusion的API接口,进行下一步的「文生图」动作。
将音频发送到LP-Music-Caps以生成音频字幕,然后使用Llama2大模型将其转换为说明性图像描述,最后运行Stable Diffusion XL以从音频生成图像!
注意:音频仅能推理前30秒。
需要网络免费
AI教程资讯更多
AI教程资讯 更多

人工智能医学大模型“Med-Go”正式发布
更新时间:2025-02-17
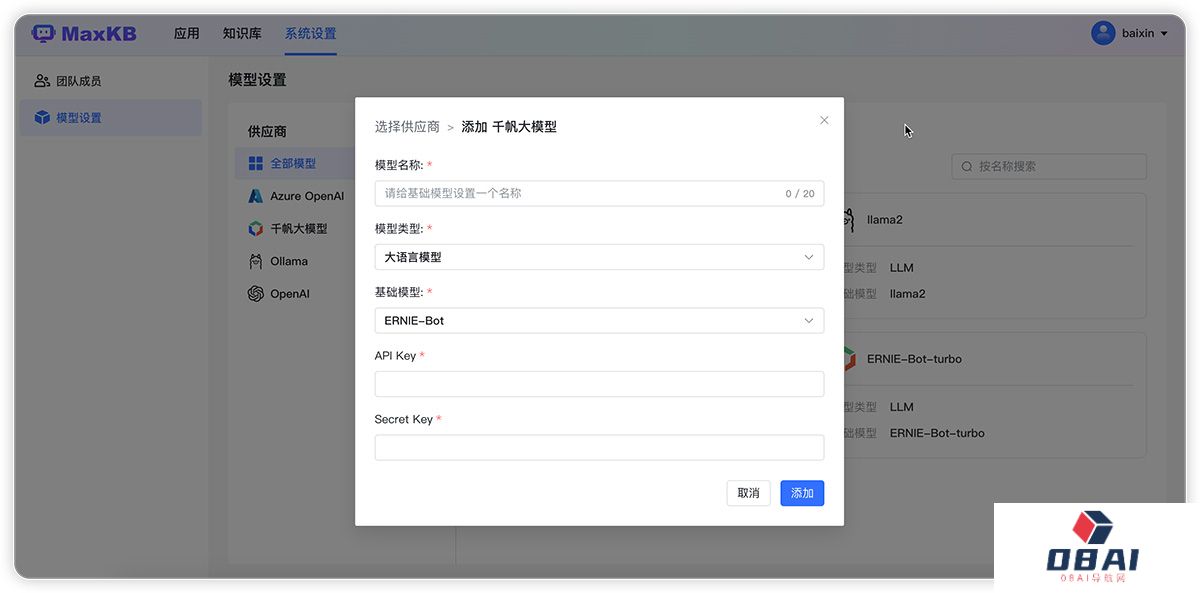
MaxKB:基于LLM大语言模型的知识库问答系统
更新时间:2024-12-10
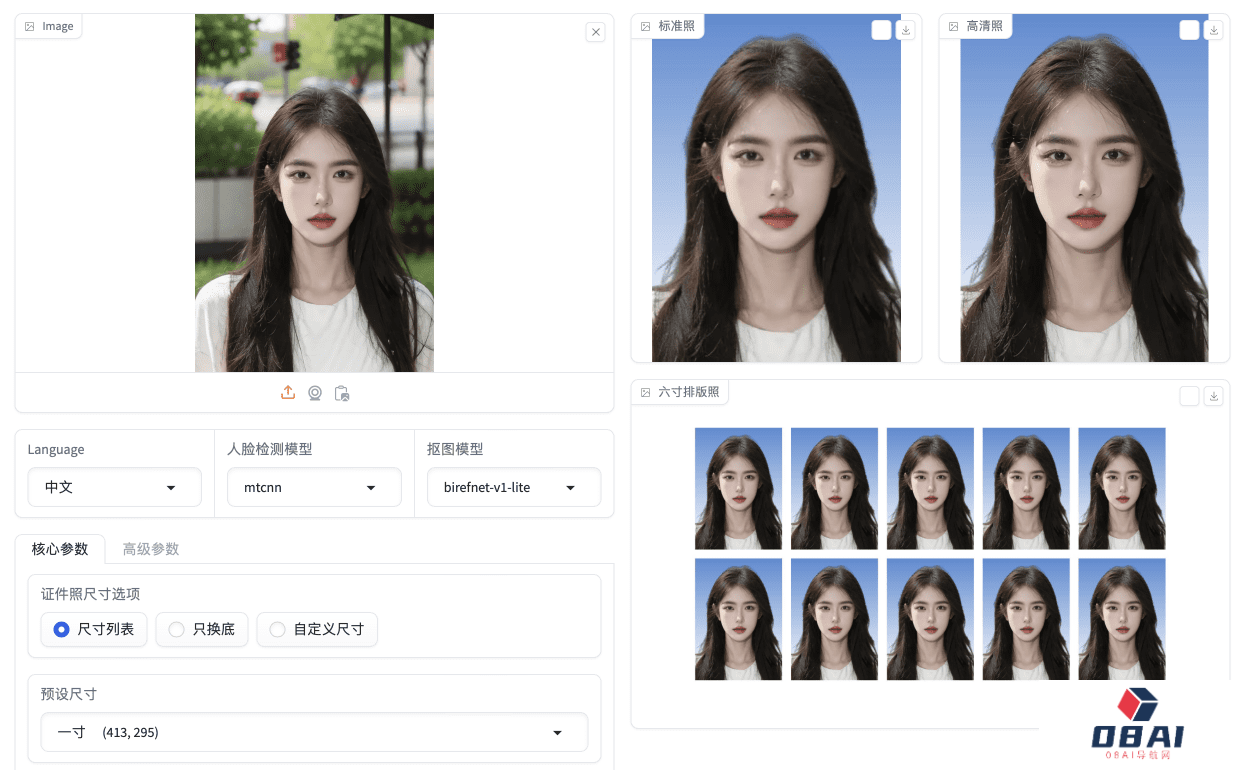
HivisionIDPhotos:一款轻量高效的AI证件照制作工具
更新时间:2024-12-13
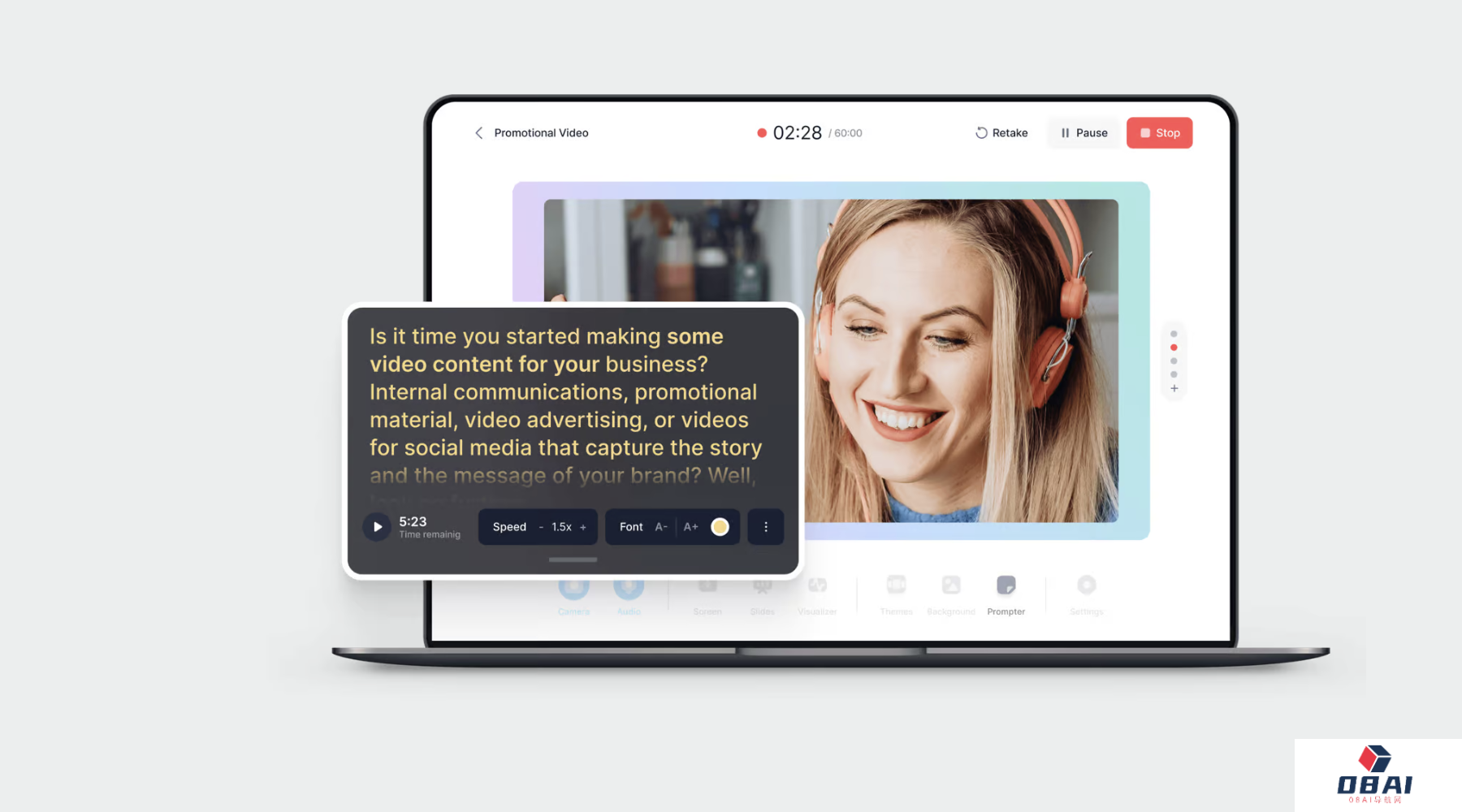
2024 年8个最佳提词器工具推荐|短视频创作者必备
更新时间:2024-12-17
高考大模型测评_豆包文科成绩领先
更新时间:2024-12-26
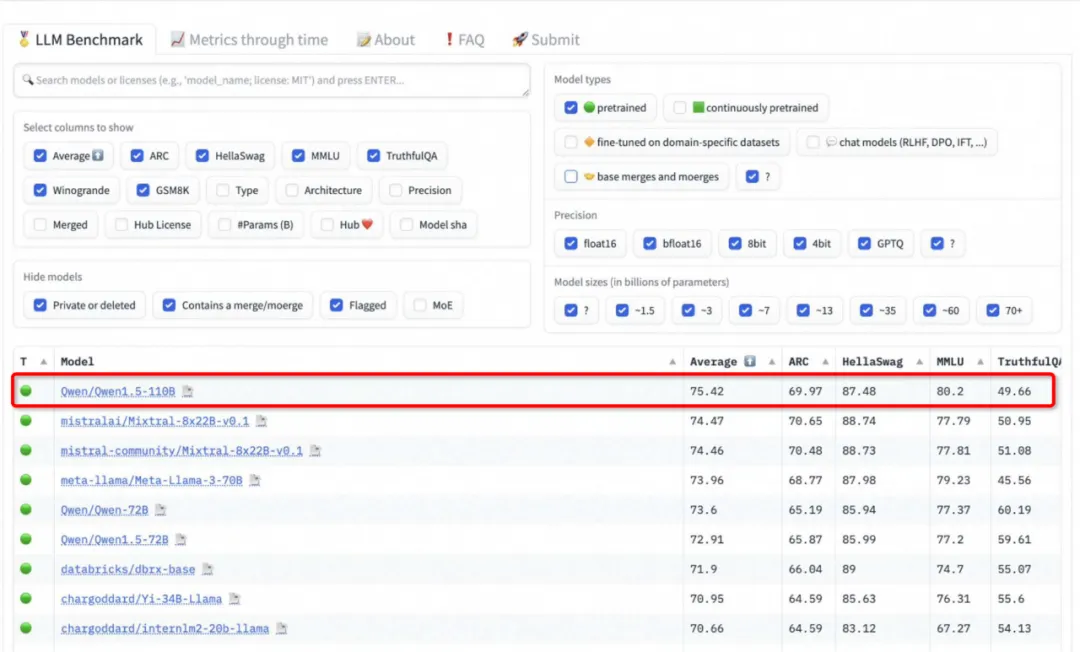
实测通义大模型2.5:闭源赶超GPT-4 Turbo,开源击败Llama-3 70B,红遍全球的国产开源中文大模型
更新时间:2024-12-26

WPS AI全面测评_WPS AI使用教学_WPS AI实用指南
更新时间:2024-12-30

通义听悟有什么黑科技_通义听悟功能介绍
更新时间:2025-01-06
通义听悟有什么能力_通义听悟有什么功能
更新时间:2025-01-06

人工智能专家王资凯:媒体从业人员要保持开放心态和对新工具的敏感性
更新时间:2025-01-20